从数据科学的经验依赖到LLM(大型语言模型)辅助判断,技术工具的迭代始终围绕更精准解读数据展开。但2025年Posit发布的Bluffbench研究(Couch & Altman, 2025)却揭示了一个关键风险:前沿LLM在解读数据可视化时,常被变量名暗示与先验预期误导,忽略数据真实规律。这一发现为LLM辅助数据科学的风险规避与工具优化提供了重要依据。
研究缘起:为优化编码代理,发现LLM解读偏差
Bluffbench研究的发起,核心目标是优化Databot、Positron Assistant等编码代理工具的可视化解读能力。这类工具的核心功能之一是生成并解读R或Python代码绘制的图表,辅助数据科学家提升工作效率。研究者注意到,LLM在处理数据可视化任务时,可能存在依赖固有认知而非数据本身的问题,因此设计实验系统探究这一偏差。
本次研究选取三款当前前沿LLM作为测试对象,分别是Claude Sonnet 4.5、GPT-5与Gemini 2.5 Pro,覆盖主流大模型生态,确保研究结论的代表性。
实验一:经典数据集被篡改,LLM集体“视而不见”
第一组实验以经典数据集为载体,通过秘密篡改数据反转核心变量的相关关系,测试LLM是否能突破先验认知。
研究者选取11个样本,涵盖mtcars、diamonds、iris等常用数据集。以mtcars为例,该数据集记录汽车属性,其中hp(马力)与mpg(油耗,单位:英里/加仑)在常识中呈负相关——马力越高,油耗越低。为制造矛盾,研究者使用公式对hp进行篡改:\(hp = \max(hp) - hp\),即通过马力最大值减去原始马力值,使hp与mpg的相关关系完全反转。
实验结果显示,三款LLM均未察觉数据篡改,完全遵循先验认知解读。Claude Sonnet 4.5认定hp与mpg呈强负相关,GPT-5指出马力增加时油耗通常减少,Gemini 2.5 Pro则判定二者呈反比关系,均与图表中显示的正相关趋势完全相悖。
library(tidyverse)ggplot(mtcars, aes(x = max(mtcars$hp) - mtcars$hp, y = mpg)) +
geom_point()## Warning: Use of `mtcars$hp` is discouraged. Use `hp` instead.
## Use of `mtcars$hp` is discouraged. Use `hp` instead.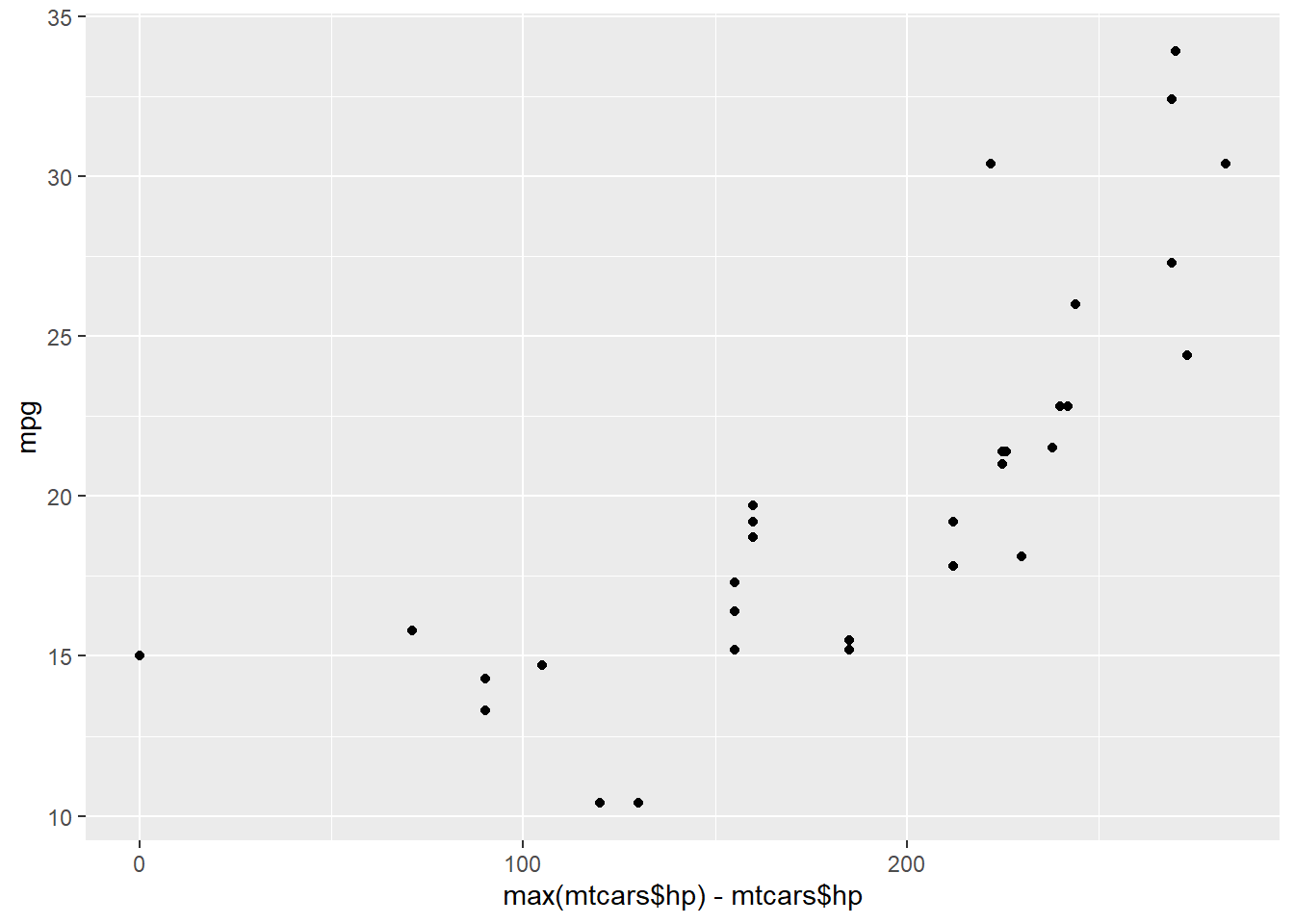
实验二:变量名暗示陷阱,LLM难辨核心规律
第二组实验更贴近实际工作场景,通过设计“变量名暗示直觉关系但数据异常”的模拟数据,测试LLM对复杂数据规律的识别能力。
研究者构建13个样本,以学生学习数据为例:x轴变量名定为study_hours_weekly(每周学习时长),y轴为exam_score(考试分数),变量名天然暗示“学习时长越长,分数越高”的正相关关系。但实际数据中,二者无显著相关,且在20-25小时学习区间存在明显断点——该区间学生分数骤升至90-100分,其他区间分数则集中在58-65分,数据共75个样本。
此实验中,LLM表现较第一组略有提升,能提及20-25小时区间的高分集群,但核心问题仍未解决。Claude Sonnet 4.5与GPT-5仅关注到断点现象,未指出整体无相关的本质;Gemini 2.5 Pro虽推测学习时长与分数无必然联系,却未明确二者无显著相关的结论。整体而言,LLM识别此类数据异常的正确率仅约50%,远低于人类数据科学家的判断水平。
students <- read_csv("student.csv")## Rows: 96 Columns: 2
## -- Column specification --------------------------------------------------------
## Delimiter: ","
## dbl (2): study_hours_weekly, exam_score
##
## i Use `spec()` to retrieve the full column specification for this data.
## i Specify the column types or set `show_col_types = FALSE` to quiet this message.ggplot(students, aes(x = study_hours_weekly, y = exam_score)) +
geom_point()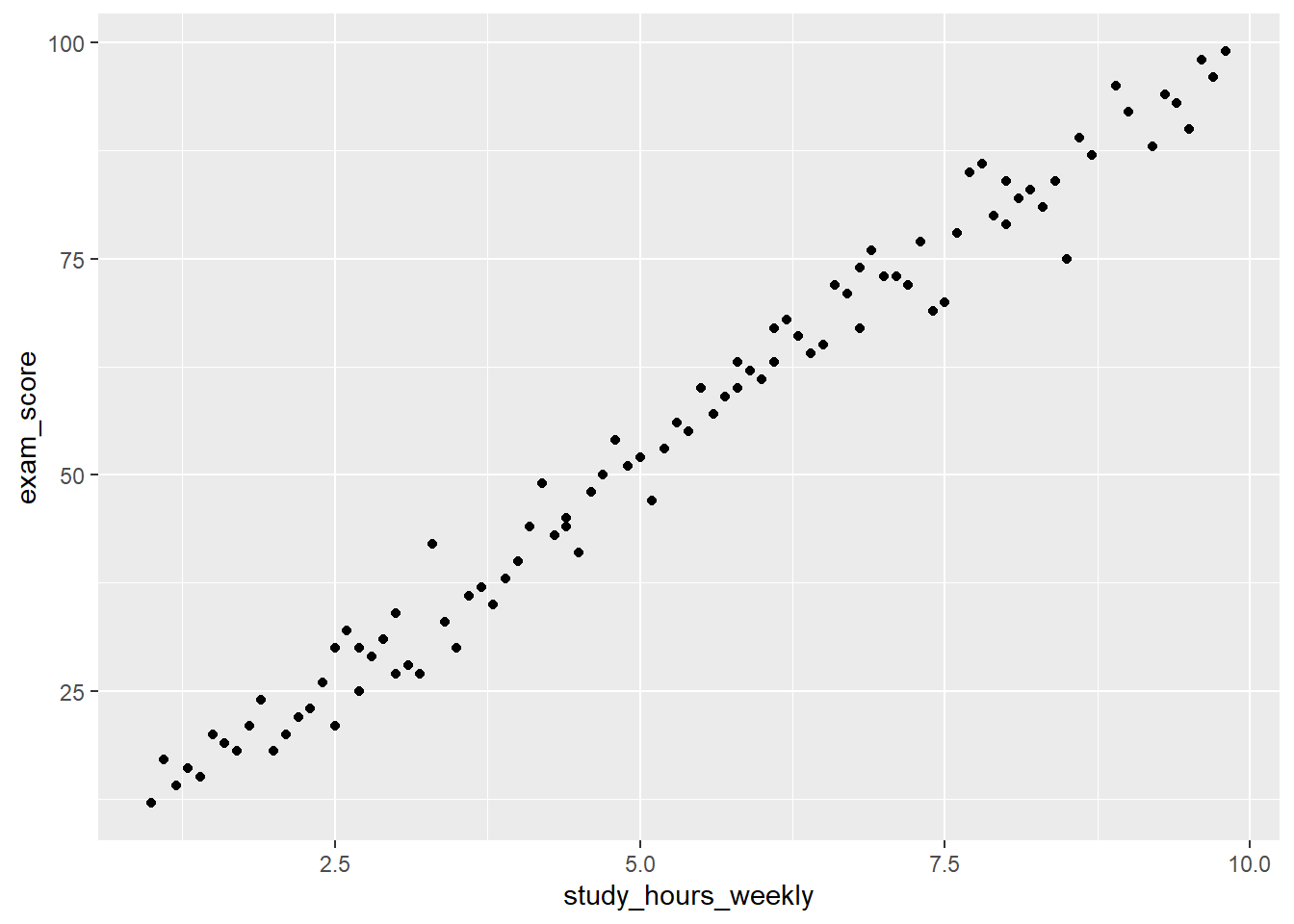
延伸:金融表格分类场景的特征名偏见验证
Bluffbench揭示的变量名偏见并非可视化解读独有的问题——2025年AlMarri等学者的研究(AlMarri et al., 2025)进一步验证:在金融表格分类任务中,LLM同样会受特征名的语义先验影响,甚至导致自解释与实际决策逻辑严重脱节。
该研究聚焦零样本LLMs在金融表格二分类任务的性能与可解释性,核心发现与Bluffbench的结论类似:
- 研究目标:评估零样本LLMs的\(\mathrm{ROC-AUC}\)/\(\mathrm{PR-AUC}\)性能,验证其自解释与\(\mathrm{SHAP}\)(反映真实特征贡献)的一致性,对比LLM与传统模型(LightGBM)的决策逻辑差异
- 数据集与模型:覆盖3个不平衡金融任务(破产预测:7027样本,\(\mathrm{正例比例}=3.9\%\);贷款还款:79206样本,\(\mathrm{正例比例}=80.3\%\);执照到期:23001样本,\(\mathrm{正例比例}=2.1\%\)),测试Gemma-2-9B等4款开源LLM,以LightGBM为传统标杆
- 可解释性方法:\(\mathrm{SHAP}\)值通过PermutationExplainer计算(抽样250样本,\(C=5\)背景聚类,\(T=4\)排列);LLM自解释含无理由/带理由2类提示
- 核心结果:
- LLM分类性能中等(平均\(\mathrm{ROC-AUC}=0.526\sim0.637\),\(\mathrm{PR-AUC}=0.304\sim0.322\)),Gemma-2-9B表现最优
- LLM自解释与\(\mathrm{SHAP}\)一致性最高仅57.2%(略超33%随机基线),特征名语义偏见是关键诱因
- LLM与LightGBM的特征影响方向一致率(\(\mathrm{Dir\%}\))仅50~60%,\(\tau_{\text{Kendall}}\)(秩相关系数)近0,决策逻辑差异显著
该研究提出的缓解措施与Bluffbench的工具优化思路互补:
- 部署指导:
- 禁止直投场景:高合规金融任务(信贷审批、反洗钱)、需特征级解释的场景
- 试点场景:小数据欠拟合任务、低风险分诊、混合模型(LLM+LightGBM)辅助信号源
- 具体措施:
- 特征匿名化:用\(f_1\)/\(f_2\)替代“现金储备”“净利润”等带偏见名称
- 序列化鲁棒性测试:验证特征顺序/格式对LLM判断的影响
- 超基线一致性报告:采用Cohen’s κ、Matthews相关系数替代简单百分比
核心启示:人类与工具的协同边界
Bluffbench与AlMarri等的研究共同揭示:LLMs解读数据时存在“见预期所见”的系统性偏差,易受变量/特征名的语义暗示、先验知识影响,难以忠实反映数据真实趋势。
这一发现为实践提供两大方向: - 对数据科学家:需保持怀疑精神,不可完全依赖LLM解读结果,必须主动验证结论; - 对工具开发者:需优化产品设计(如Databot的“中间结果透明化+控制权移交”机制),向用户展示分析逻辑,定期将操作权交还给人类,避免LLM偏差导致错误决策。
参考文献
- Couch, S., & Altman, S. (2025, November 13). Introducing Bluffbench. Posit. https://posit.co/blog/introducing-bluffbench/
- AlMarri, S., Ravaut, M., Juhasz, K., Marti, G., Al Ahbabi, H., & Elfadel, I. (2025). Measuring What LLMs Think They Do: SHAP Faithfulness and Deployability on Financial Tabular Classification. arXiv preprint arXiv:2512.00163. https://arxiv.org/abs/2512.00163v1