本文于2020-10-10更新。 如发现问题或者有建议,欢迎提交 Issue
library(visdat)
library(tidyverse)
library(naniar)
library(rmarkdown)1 缺失值位置
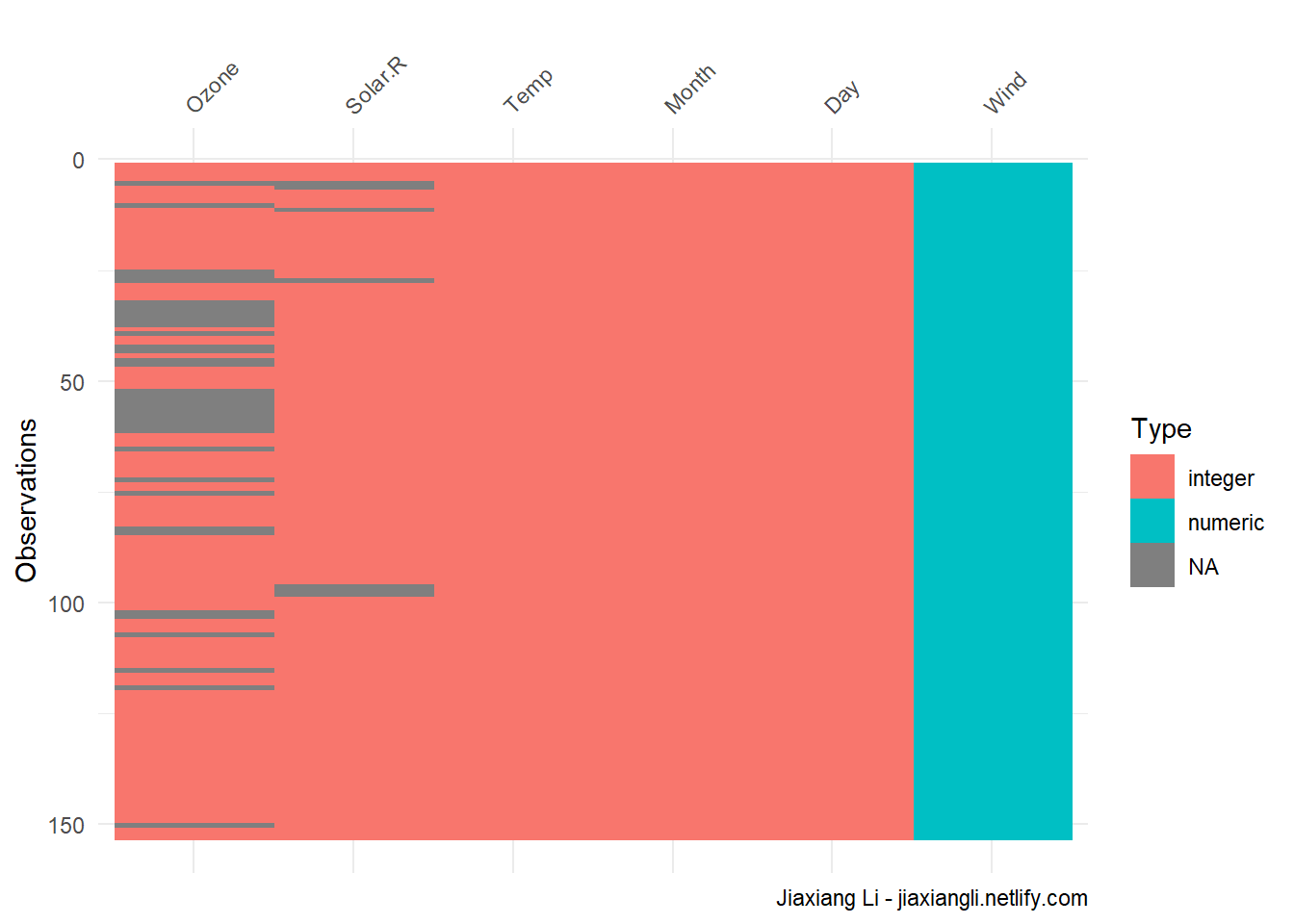
vis_dat(airquality) +
labs(
caption = "Jiaxiang Li - jiaxiangli.netlify.com"
)
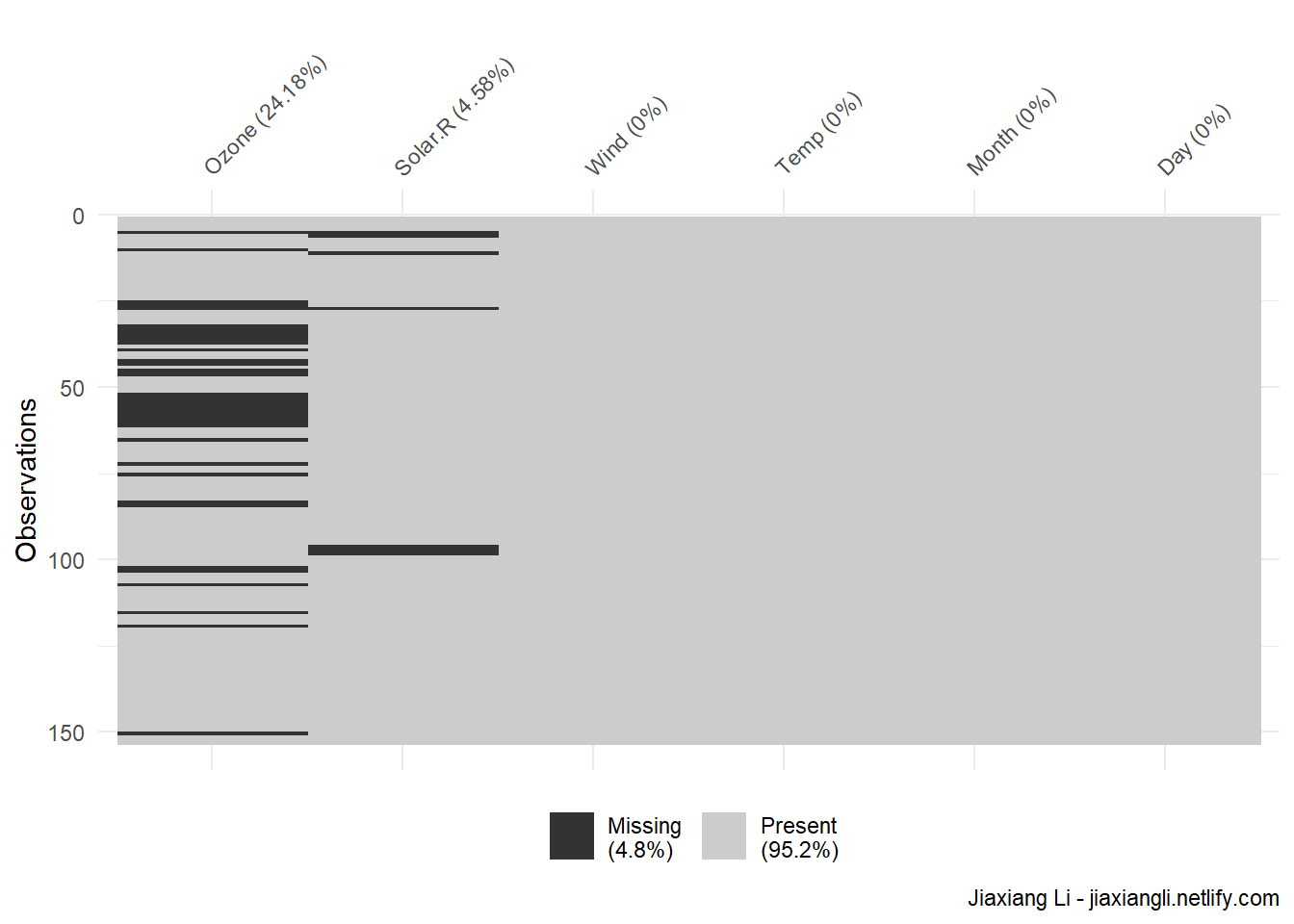
vis_miss(airquality) +
labs(
caption = "Jiaxiang Li - jiaxiangli.netlify.com"
)
- 缺点是不能进行
ggplot2函数的叠加。 ( Github )
2 缺失值分布
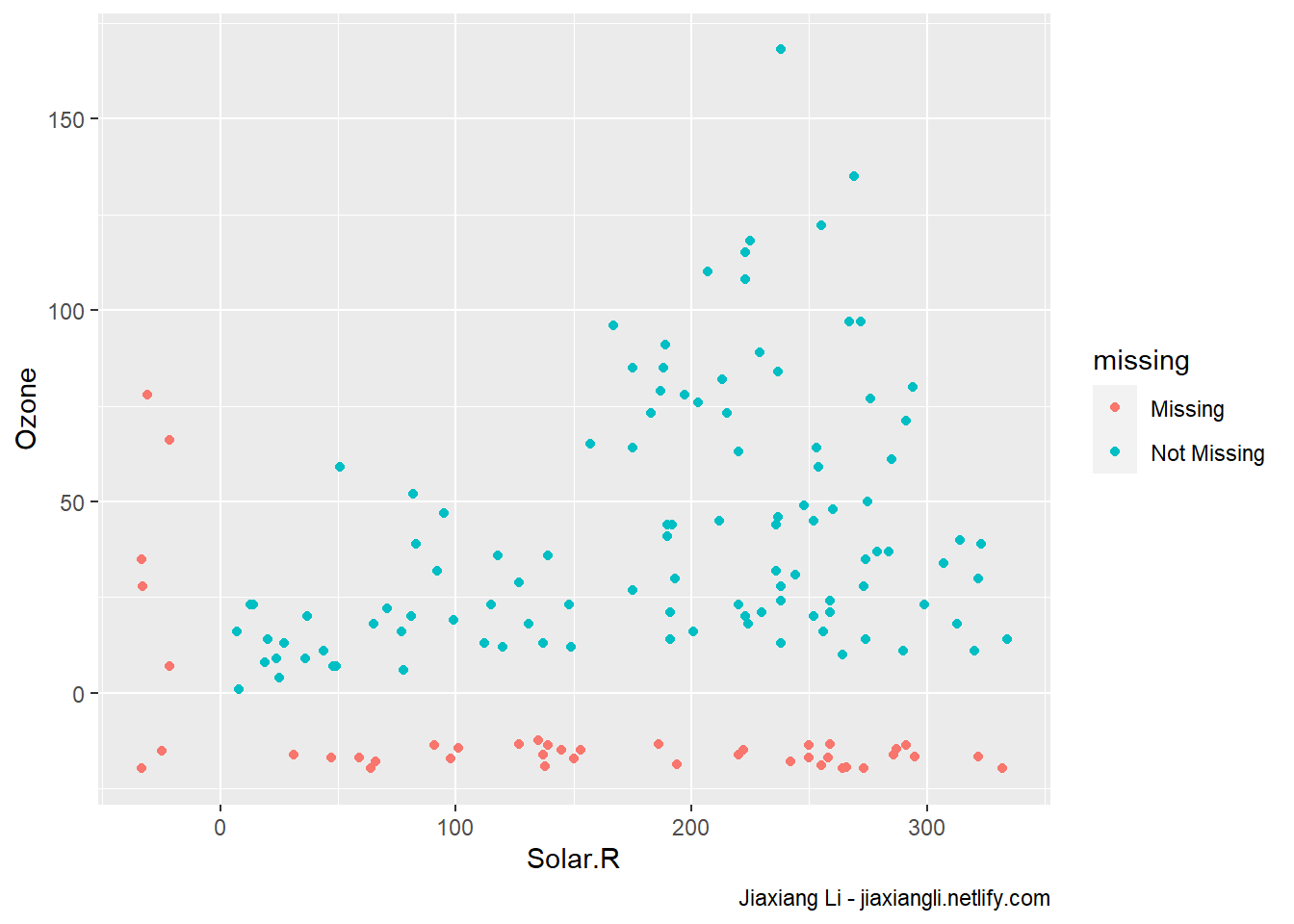
One approach to visualising missing data comes from
ggobiandmanet, where we replace “NA” values with values 10% lower than the minimum value in that variable. (Tierney 2018c)
缺失值的展示方法中,一种是使用最小值还要小10%的值来代替,这样就可以进行散点图等方式进行展示。
ggplot(airquality,
aes(x = Solar.R,
y = Ozone)) +
geom_miss_point() +
labs(
caption = "Jiaxiang Li - jiaxiangli.netlify.com"
)
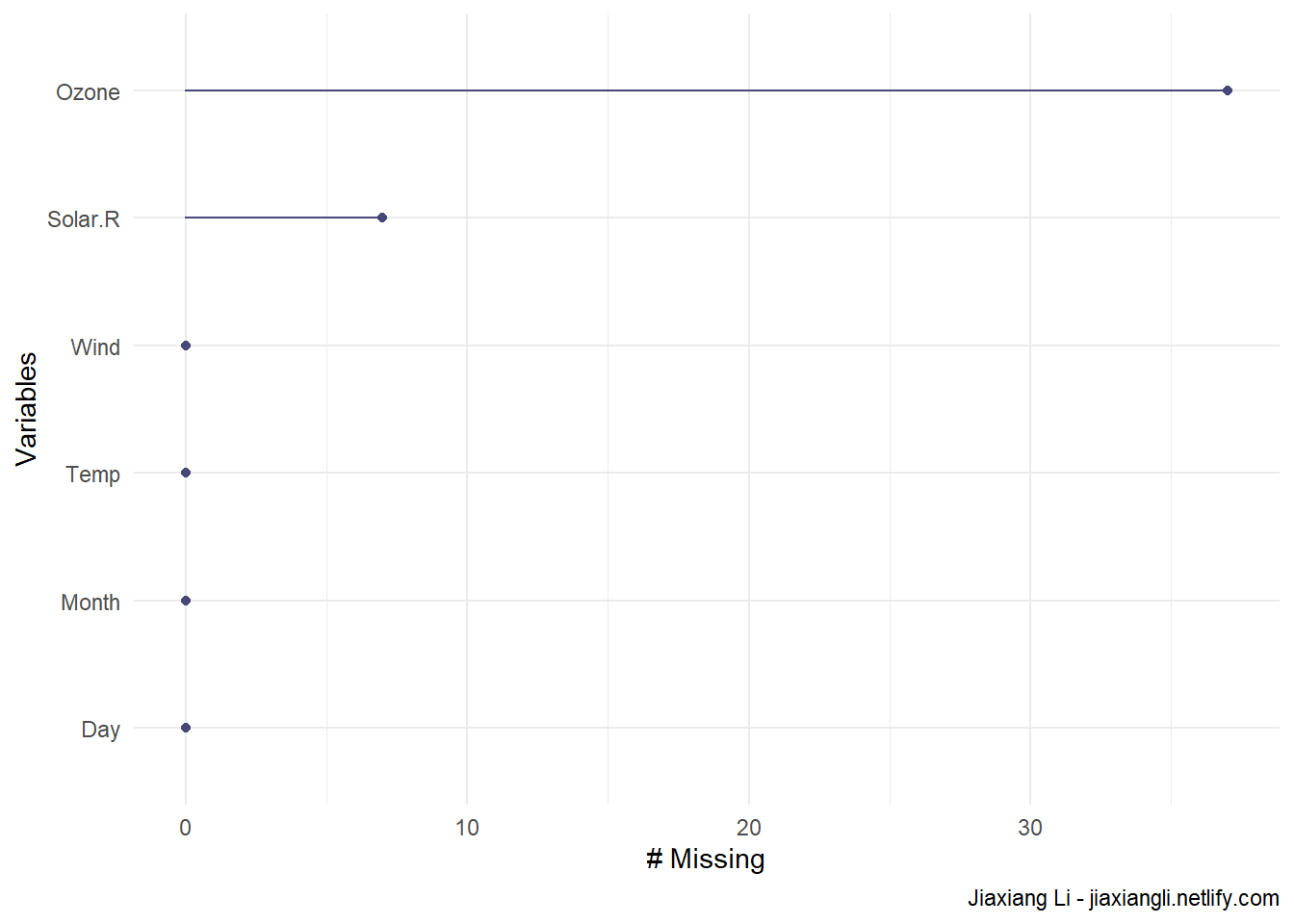
3 缺失值数量
gg_miss_var(airquality) +
labs(
caption = "Jiaxiang Li - jiaxiangli.netlify.com"
)
4 样本缺失值情况
miss_case_summary(airquality)## # A tibble: 153 x 3
## case n_miss pct_miss
## <int> <int> <dbl>
## 1 5 2 33.3
## 2 27 2 33.3
## 3 6 1 16.7
## 4 10 1 16.7
## 5 11 1 16.7
## 6 25 1 16.7
## 7 26 1 16.7
## 8 32 1 16.7
## 9 33 1 16.7
## 10 34 1 16.7
## # ... with 143 more rowscase是行的indexn_miss是某行缺失值的个数,pct_miss是某行缺失值的比例。
miss_case_table(airquality)## # A tibble: 3 x 3
## n_miss_in_case n_cases pct_cases
## <int> <int> <dbl>
## 1 0 111 72.5
## 2 1 40 26.1
## 3 2 2 1.31再按照n_miss_in_case进行了汇总。
4.1 样本缺失值预测
根据miss_case_summary可以知道每个样本的缺失情况,可以对这个缺失率或者值,进行模型预测,看哪个变量比较显著。
library(rpart)
library(rpart.plot)## Warning: 程辑包'rpart.plot'是用R版本3.6.3 来建造的airquality %>%
add_prop_miss() %>%
rpart(prop_miss_all ~ ., data = .) %>%
prp(type = 4, extra = 101, prefix = "Prop. Miss = ") ## Warning: Cannot retrieve the data used to build the model (so cannot determine roundint and is.binary for the variables).
## To silence this warning:
## Call prp with roundint=FALSE,
## or rebuild the rpart model with model=TRUE.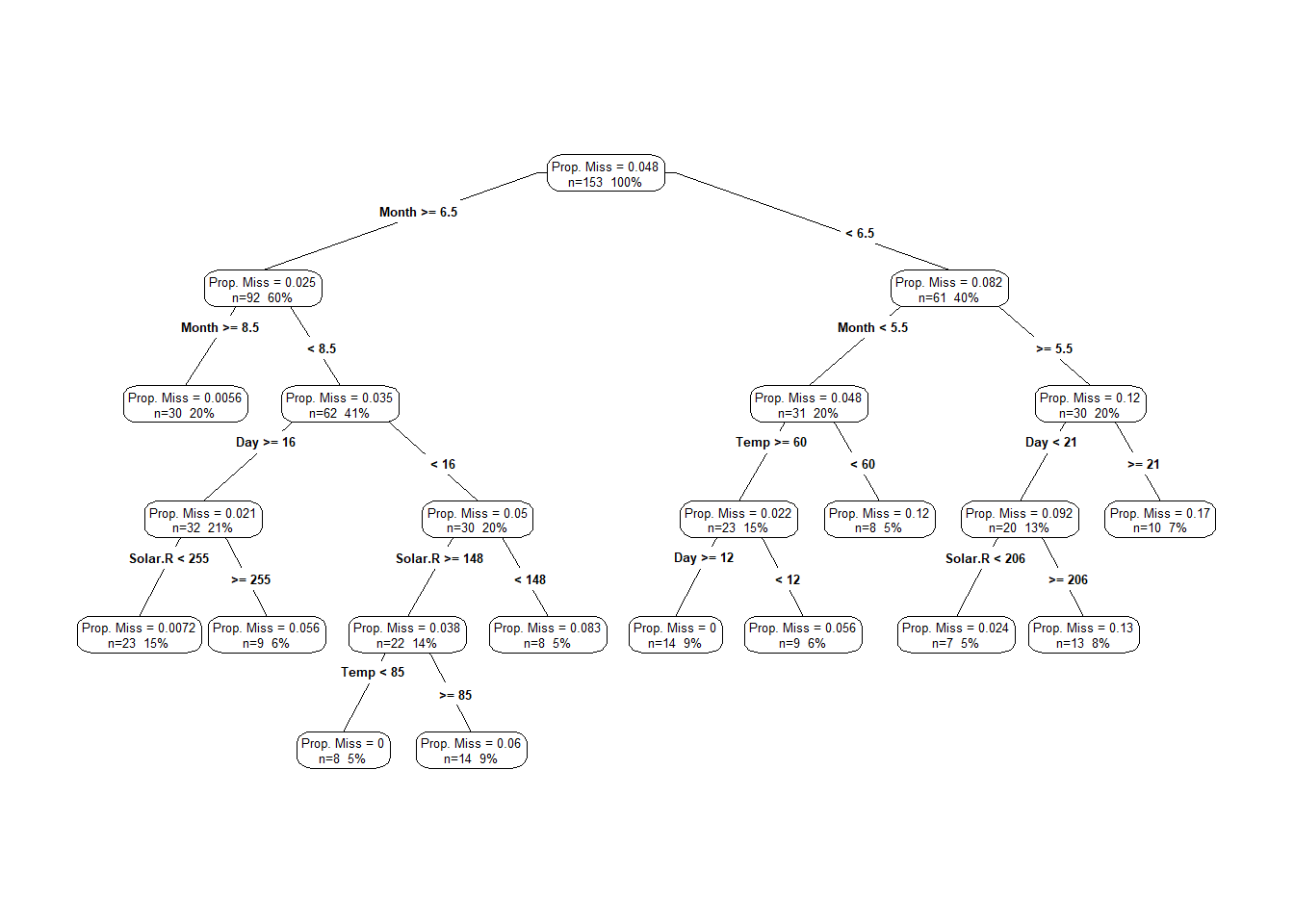
5 变量缺失值情况
miss_var_summary(airquality)## # A tibble: 6 x 3
## variable n_miss pct_miss
## <chr> <int> <dbl>
## 1 Ozone 37 24.2
## 2 Solar.R 7 4.58
## 3 Wind 0 0
## 4 Temp 0 0
## 5 Month 0 0
## 6 Day 0 0miss_var_table(airquality)## # A tibble: 3 x 3
## n_miss_in_var n_vars pct_vars
## <int> <int> <dbl>
## 1 0 4 66.7
## 2 7 1 16.7
## 3 37 1 16.7pedestrian %>%
group_by(month) %>%
miss_var_summary() %>%
filter(variable == "hourly_counts")## # A tibble: 12 x 4
## # Groups: month [12]
## month variable n_miss pct_miss
## <ord> <chr> <int> <dbl>
## 1 January hourly_counts 0 0
## 2 February hourly_counts 0 0
## 3 March hourly_counts 0 0
## 4 April hourly_counts 552 19.2
## 5 May hourly_counts 72 2.42
## 6 June hourly_counts 0 0
## 7 July hourly_counts 0 0
## 8 August hourly_counts 408 13.7
## 9 September hourly_counts 0 0
## 10 October hourly_counts 412 7.44
## 11 November hourly_counts 888 30.8
## 12 December hourly_counts 216 7.26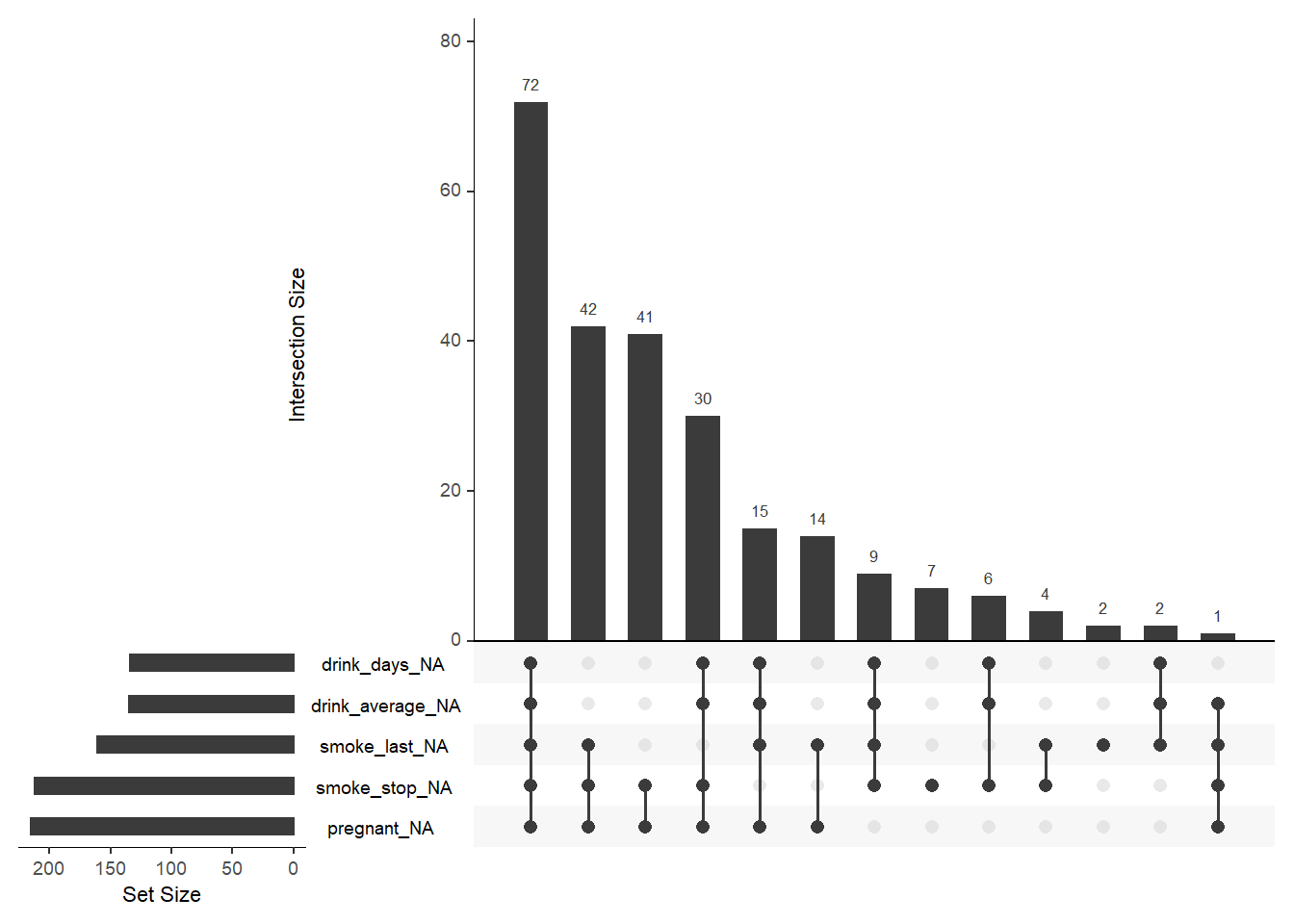
6 填补缺失值
library(simputation)## Warning: 程辑包'simputation'是用R版本3.6.3 来建造的##
## 载入程辑包:'simputation'## The following object is masked from 'package:naniar':
##
## impute_medianocean_imp <- oceanbuoys %>%
bind_shadow() %>%
impute_lm(air_temp_c ~ wind_ew + wind_ns) %>%
impute_lm(humidity ~ wind_ew + wind_ns) %>%
impute_lm(sea_temp_c ~ wind_ew + wind_ns) %>%
add_label_shadow() %>%
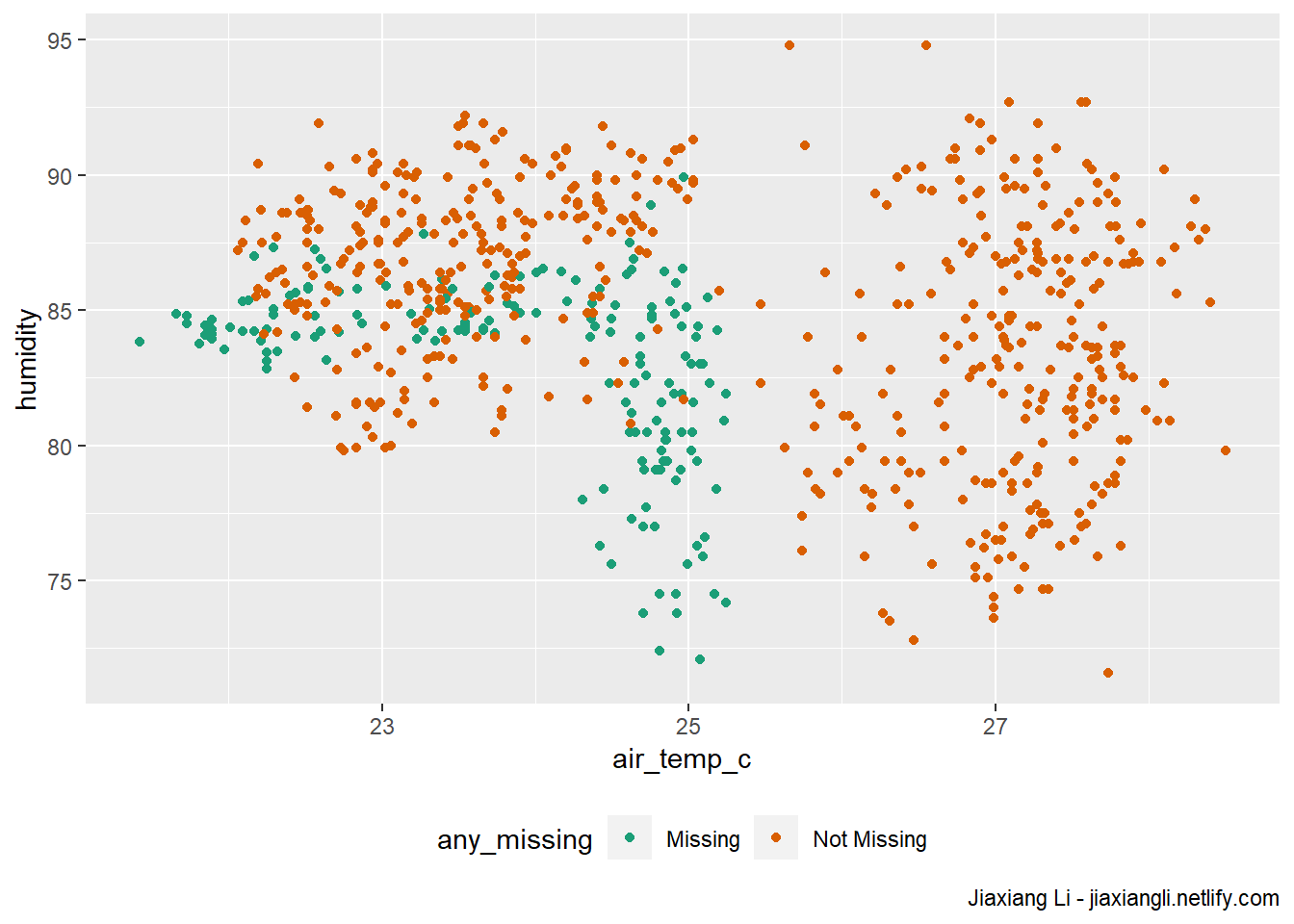
paged_table()add_label_shadow函数打上标记any_missing。
(Tierney 2018a)
library(ggplot2)
ggplot(ocean_imp,
aes(x = air_temp_c,
y = humidity,
color = any_missing)) +
geom_point() +
scale_color_brewer(palette = "Dark2") +
theme(legend.position = "bottom") +
labs(
caption = "Jiaxiang Li - jiaxiangli.netlify.com"
)
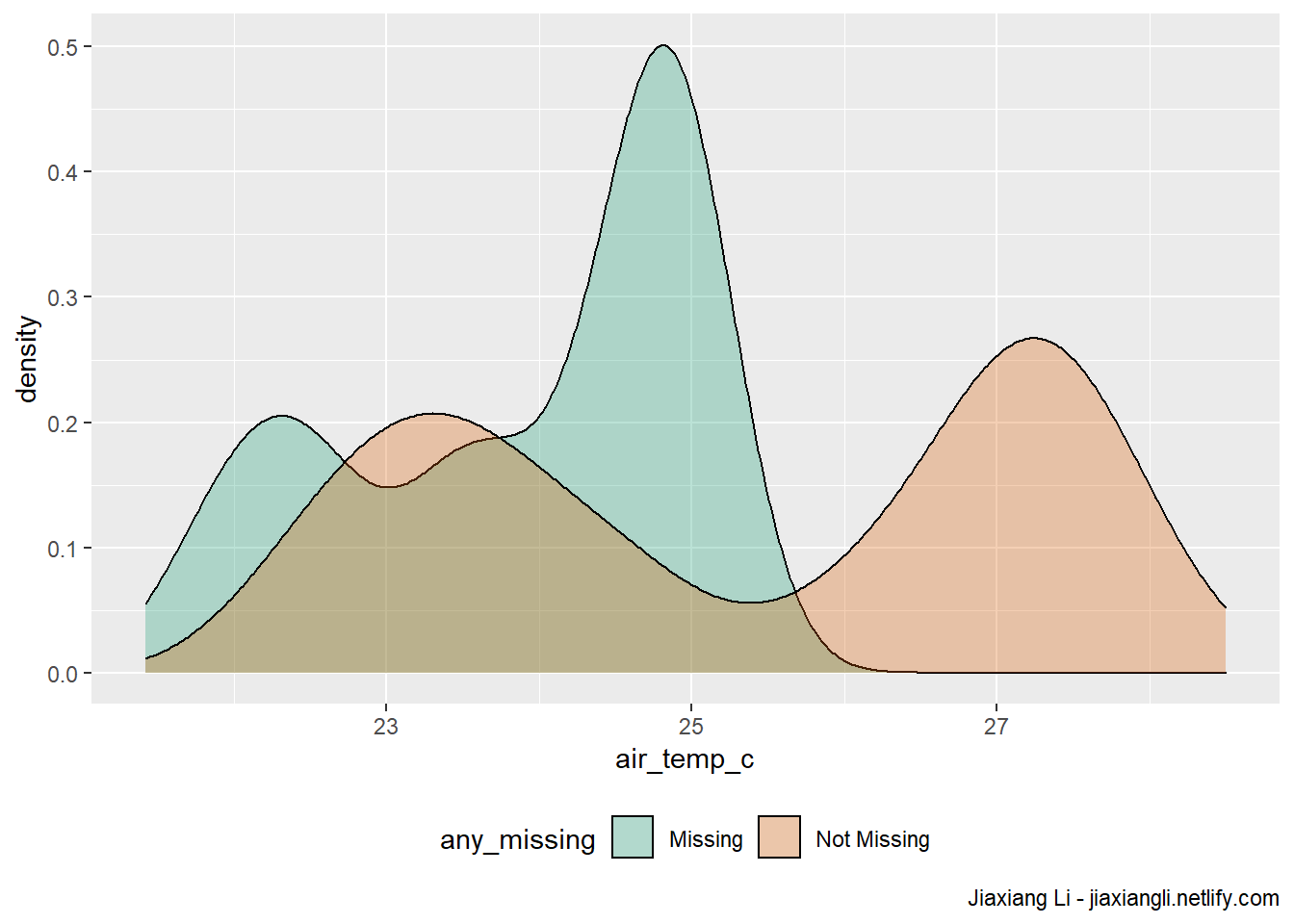
ggplot(ocean_imp,
aes(x = air_temp_c,
fill = any_missing)) +
geom_density(alpha = 0.3) +
scale_fill_brewer(palette = "Dark2") +
theme(legend.position = "bottom") +
labs(
caption = "Jiaxiang Li - jiaxiangli.netlify.com"
)
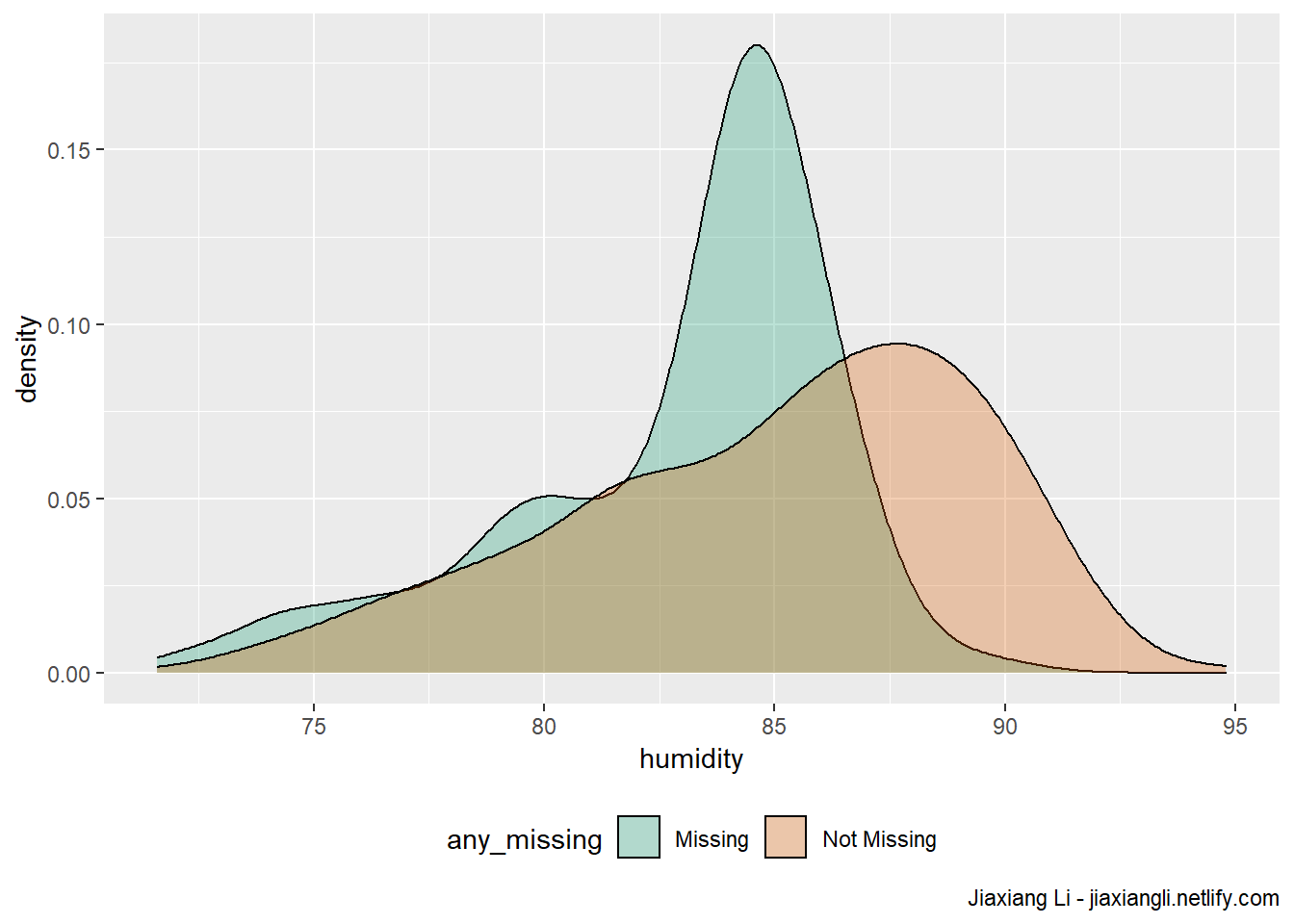
ggplot(ocean_imp,
aes(x = humidity,
fill = any_missing)) +
geom_density(alpha = 0.3) +
scale_fill_brewer(palette = "Dark2") +
theme(legend.position = "bottom") +
labs(
caption = "Jiaxiang Li - jiaxiangli.netlify.com"
)
7 Cases
library(data.table)
library(tidyverse)
library(visdat)
library(naniar)
# data <- fread('ldfilter_cbind.txt')
data <- fread(here::here('../tutoring2/pansiyu/analysis/NA_inlm/ldfilter_cbind.txt'))dim(data)## [1] 683 53缺失值处理参考 naniar 使用技巧 缺失值展示 。
vis_miss(data) +
theme(text = element_text(size=10),
axis.text.x = element_text(angle=90, hjust=1)) +
labs(
caption = "Jiaxiang Li - jiaxiangli.netlify.com"
)
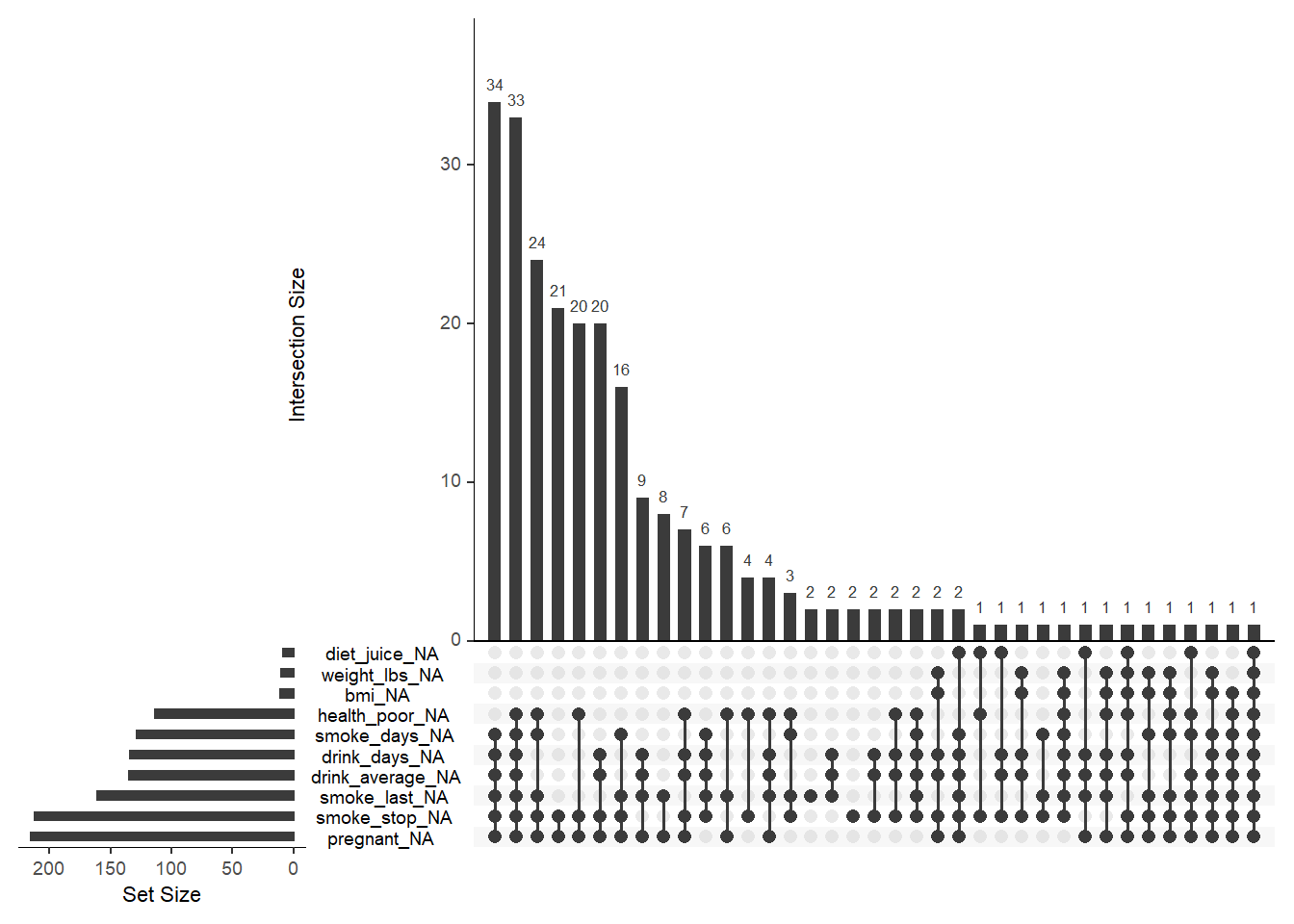
联动缺失不高。
联动缺失不高,点击前面的三角查看更多。
gg_miss_upset(data)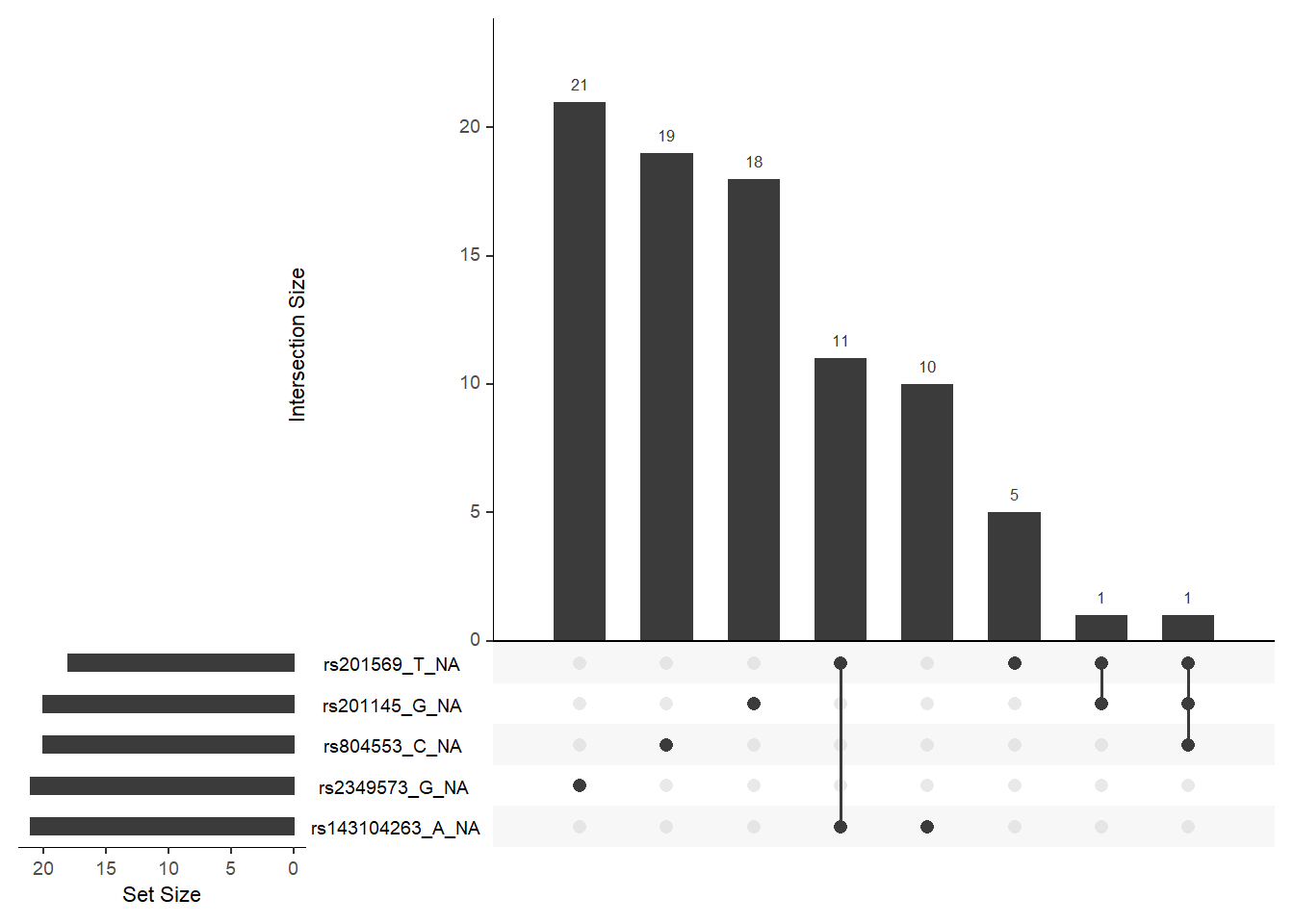
gg_miss_upset(data,
nsets = 10,
nintersects = 50)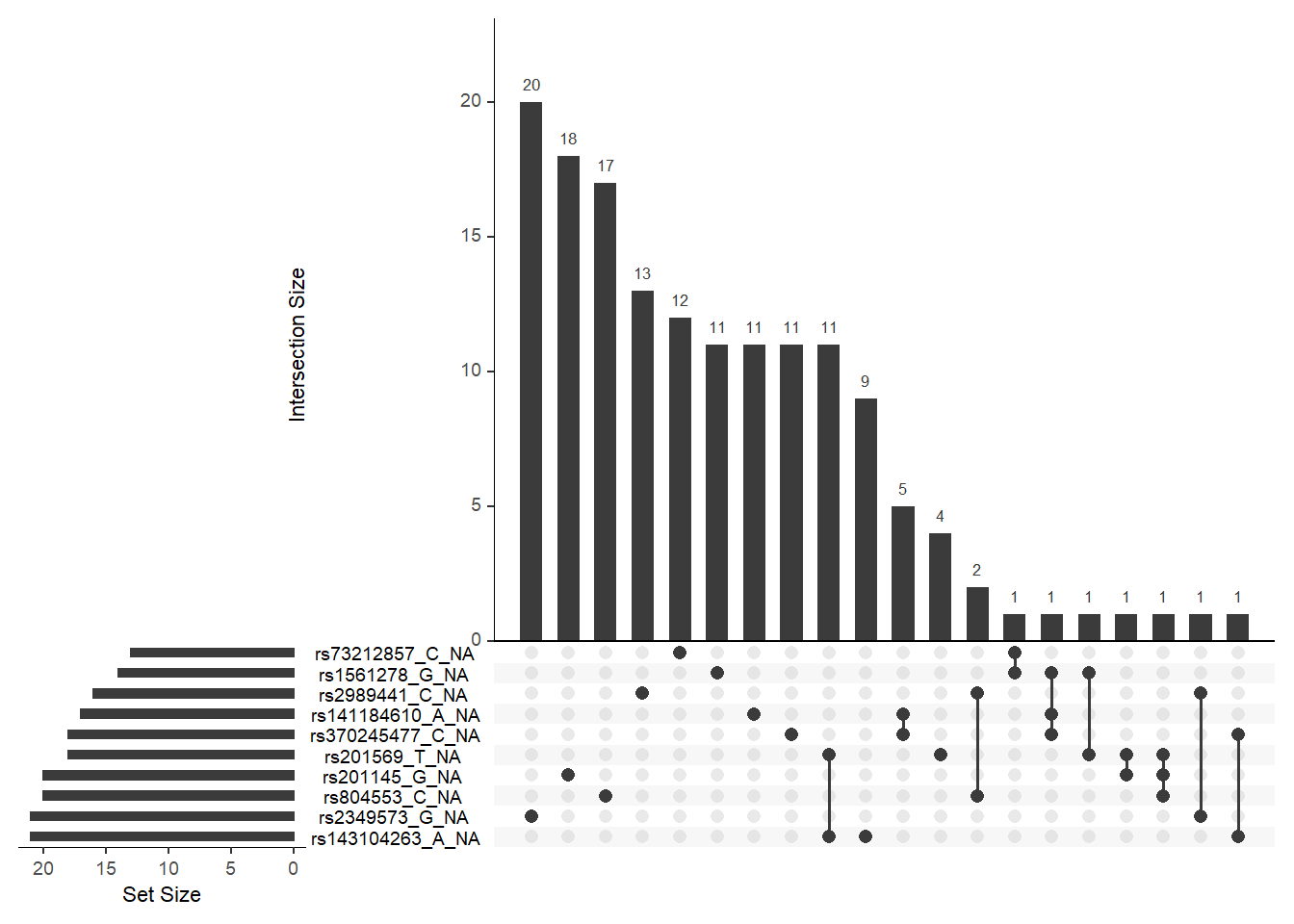
样本缺失率不高。
miss_case_summary(data)## # A tibble: 683 x 3
## case n_miss pct_miss
## <int> <int> <dbl>
## 1 106 5 9.43
## 2 154 4 7.55
## 3 10 3 5.66
## 4 15 3 5.66
## 5 26 3 5.66
## 6 74 3 5.66
## 7 129 3 5.66
## 8 213 3 5.66
## 9 231 3 5.66
## 10 372 3 5.66
## # ... with 673 more rowsmiss_case_table(airquality)## # A tibble: 3 x 3
## n_miss_in_case n_cases pct_cases
## <int> <int> <dbl>
## 1 0 111 72.5
## 2 1 40 26.1
## 3 2 2 1.31- 最多一个样本,缺失值也就5个。
变量缺失率不高。
gg_miss_var(data) +
theme(
text = element_text(size=8))+
labs(
caption = "Jiaxiang Li - jiaxiangli.netlify.com"
)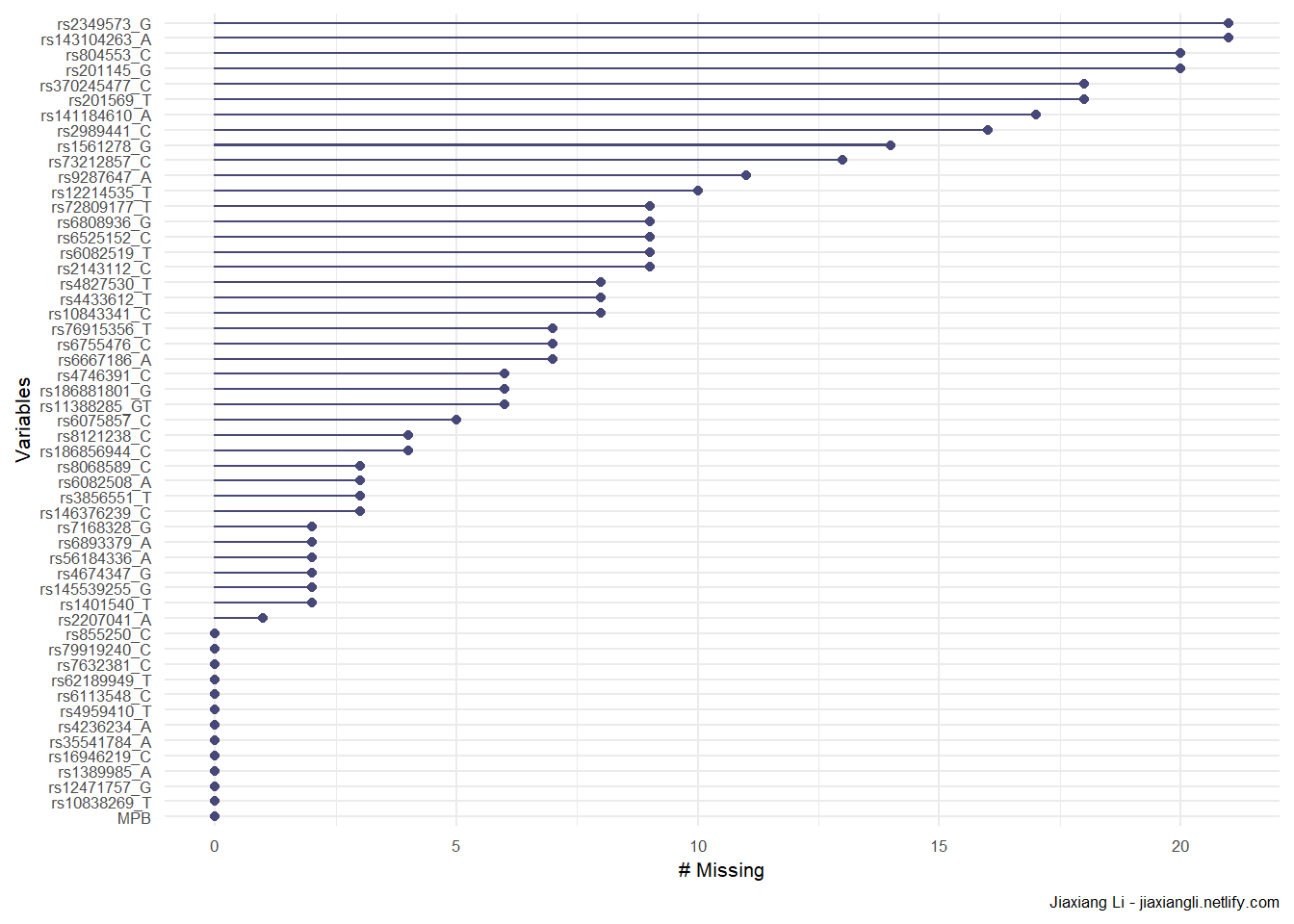
miss_var_summary(data)## # A tibble: 53 x 3
## variable n_miss pct_miss
## <chr> <int> <dbl>
## 1 rs2349573_G 21 3.07
## 2 rs143104263_A 21 3.07
## 3 rs201145_G 20 2.93
## 4 rs804553_C 20 2.93
## 5 rs370245477_C 18 2.64
## 6 rs201569_T 18 2.64
## 7 rs141184610_A 17 2.49
## 8 rs2989441_C 16 2.34
## 9 rs1561278_G 14 2.05
## 10 rs73212857_C 13 1.90
## # ... with 43 more rowsmiss_var_table(data)## # A tibble: 19 x 3
## n_miss_in_var n_vars pct_vars
## <int> <int> <dbl>
## 1 0 13 24.5
## 2 1 1 1.89
## 3 2 6 11.3
## 4 3 4 7.55
## 5 4 2 3.77
## 6 5 1 1.89
## 7 6 3 5.66
## 8 7 3 5.66
## 9 8 3 5.66
## 10 9 5 9.43
## 11 10 1 1.89
## 12 11 1 1.89
## 13 13 1 1.89
## 14 14 1 1.89
## 15 16 1 1.89
## 16 17 1 1.89
## 17 18 2 3.77
## 18 20 2 3.77
## 19 21 2 3.77library(rpart)
library(rpart.plot)
data %>%
add_prop_miss() %>%
rpart(prop_miss_all ~ ., data = .) %>%
prp(type = 4, extra = 101, prefix = "Prop. Miss = ") ## Warning: Cannot retrieve the data used to build the model (so cannot determine roundint and is.binary for the variables).
## To silence this warning:
## Call prp with roundint=FALSE,
## or rebuild the rpart model with model=TRUE.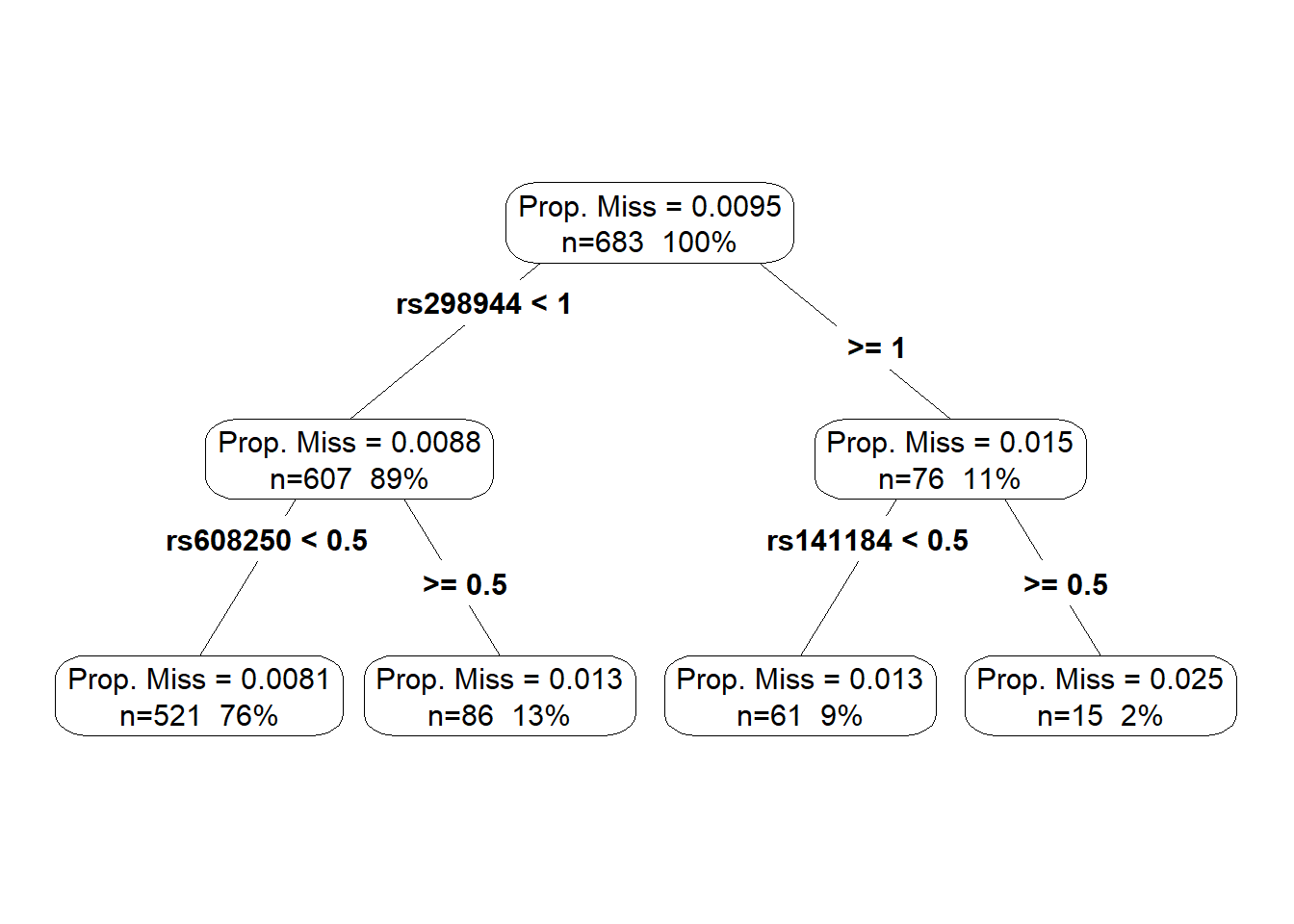
- 如图是影响缺失的主要变量。
由于缺失值不严重,因此进行lm。
library(broom)## Warning: 程辑包'broom'是用R版本3.6.3 来建造的data %>%
mutate_at(vars(-MPB)
,~fct_explicit_na(factor(.),'No_infos')) %>%
lm(MPB~.,data=.) %>%
tidy %>%
DT::datatable(
rownames = FALSE,
extensions = 'Buttons', options = list(
dom = 'Bfrtip',
buttons = c('copy', 'csv', 'excel', 'pdf', 'print')
)
)- 点击对应格式可以下载。
Tierney, Nicholas. 2018a. “Exploring Imputed Values.” 2018. http://naniar.njtierney.com/articles/exploring-imputed-values.html.
———. 2018b. “Gallery of Missing Data Visualisations.” 2018. http://naniar.njtierney.com/articles/naniar-visualisation.html.
———. 2018c. “Getting Started with Naniar.” 2018. http://naniar.njtierney.com/articles/getting-started-w-naniar.html.