本文主要记录吴恩达机器学习课程中三个核心算法的学习笔记:降维、异常检测和推荐系统。
降维(Dimensionality Reduction)
主成分分析(PCA)
PCA is to find a vector to minimize the projection errors. [@Andrew2018]

PCA的核心思想是最小化投影误差(projection errors),而不是最小化y − ŷ。
PCA算法原理

PCA作为降维技术,利用线性代数中的特征向量来实现。特征向量在空间变换时方向保持不变,这为降维提供了理论基础。
应用示例: - 股票指数构建:第一主成分方向描述了大多数股票价格的共同走势 - 构建投影误差最小的平面或曲线
anomaly detection
这里的内容是无监督学习。 假设各个x具备独立性假设,那么可以用∏来表达联合分布概率。 以此来探查datatest是否处于数据的分布的尾巴处,即异常值。

$$\begin{alignat}{2} p(x) &= p(x_1;\mu_1,\sigma_1^2) \cdots p(x_n;\mu_n,\sigma_1^n)\\ &=\prod_{j=1}^np(x_j;\mu_j,\sigma_1^j) \end{alignat}\\ \text{Anomaly if } p(x) < \epsilon$$
这里的p(x) < ϵ类似于p value。
使用μ定义outliter [@Roberts2018]
建立一个简单模型(如,ridge),产生回归方程 y = ŷ + μ̂
针对每一个μ̂i进行zscore处理, $$\nu_i = \frac{\hat \mu_i - \mathrm{E}(\hat \mu)}{\mathrm{\sigma(\hat \mu)}}$$ 对分布在三倍标准正态分布σ = 1外的样本,判定为outlier。 |νi| > 3
recommender systems
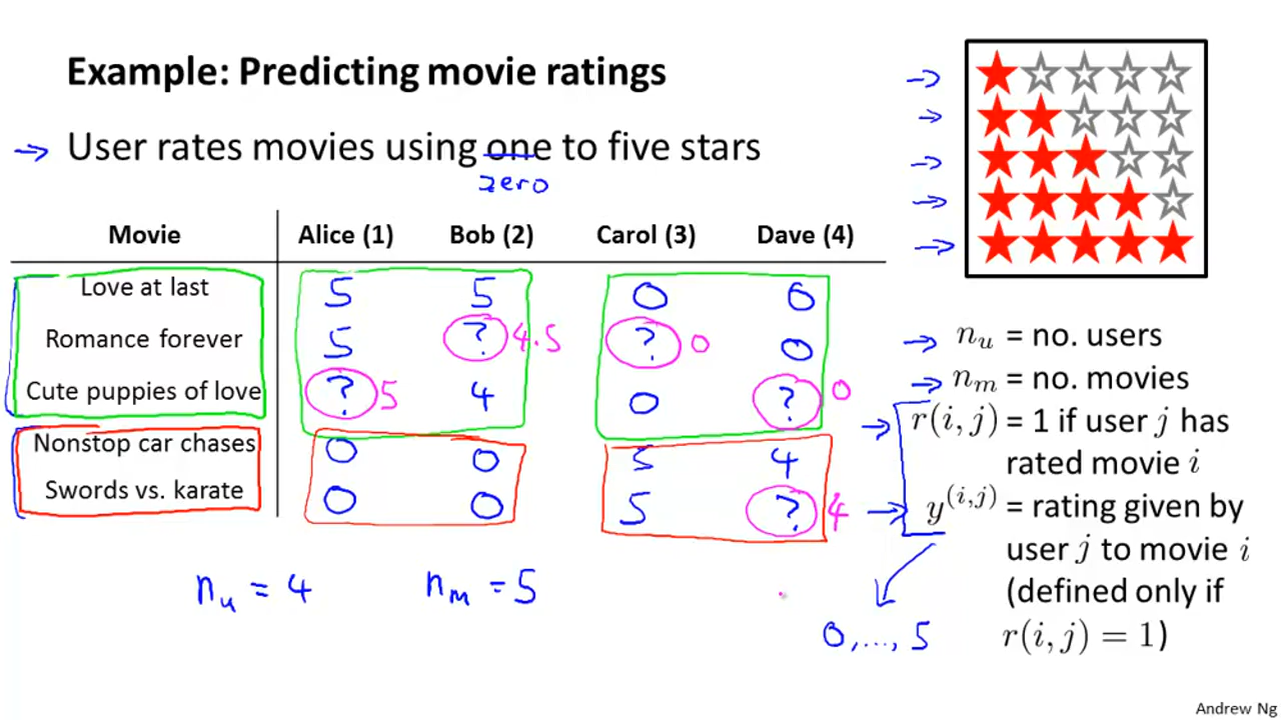
推荐器就是用已知信息,推测?的值。 [@Andrew2018]
content based approach


假设我们可以从每个人的身上得知,对x(feature)的打分,就是β,最终我们可以独立做一个OLS回归,得到ŷ,从而给电影打分,但是这不符合实际的1,所以介绍下一种方法。
collaborative filtering



- content-based-recommendations 是根据x和y,去估计x的偏好–x的参数θ。
- collaborative-filtering,是可以 先后或者 同时根据x和y,估计θ;同时根据θ和y,估计x。
对于collaborative-filtering,我们可以估计出最好的x和θ,估计出最好的x,也就是变量筛选的功能。
mean normalization
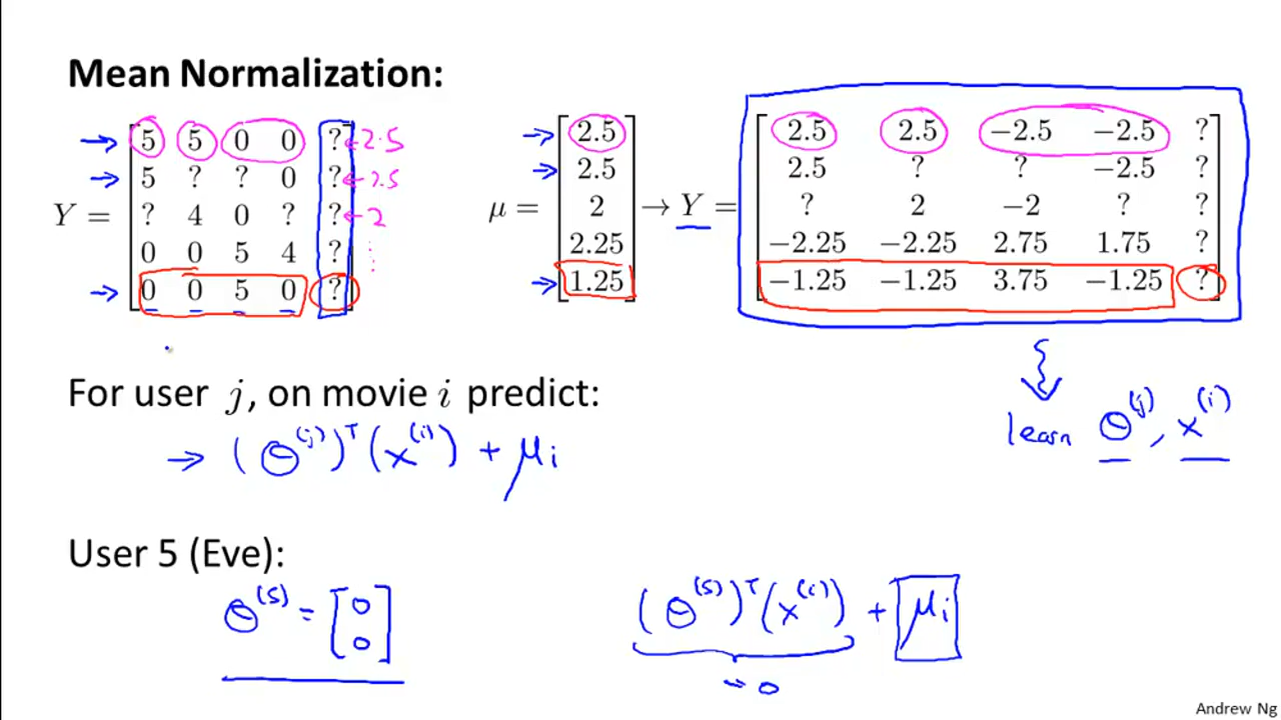
对于从来没有rate任何电影的用户来说,很可能预测所有的θ = 0,这个时候还不如用其他用户对某一个电影均值作为预测值,至少可以作为baseline。 这里可以引入mean normalization。
y − μ → estimate θ̂ → estimate θ̂x → ŷ = θ̂x + μ
参考文献
我们很难采集到每个人对一步电影全部维度的偏好。↩︎